랜덤 포레스트란?
랜덤 포레스트(Random Forest)
- 랜덤 포레스트(Random Forest)는 배깅(Bagging) 기법을 기반으로 한 앙상블 학습 모델입니다.
- 여러 개의 결정 트리(Decision Tree)를 학습시키고, 그 예측 결과를 결합하여 최종 예측을 수행합니다.
- 각 트리가 독립적으로 학습되기 때문에, 과적합을 방지하고 예측 성능을 향상시킬 수 있습니다.
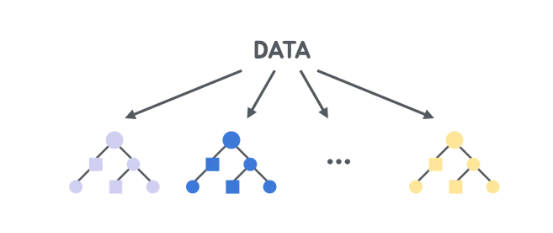
랜덤 포레스트의 주요 특징:
- 결정 트리 기반:
- 랜덤 포레스트는 여러 개의 결정 트리를 결합합니다. 각 결정 트리는 데이터의 특성에 따라 예측을 수행합니다.
- 배깅 기법 적용:
- 각 트리는 데이터 샘플의 부트스트랩 샘플(bootstrap sample)을 사용하여 훈련됩니다. 이는 원본 데이터에서 무작위로 샘플을 뽑고 중복을 허용하는 방식입니다.
- 각 트리는 독립적으로 훈련되며, 예측을 할 때 각 트리의 예측을 평균 내거나 다수결 방식으로 결합하여 최종 예측을 만듭니다.
- 특성 선택의 랜덤성:
- 트리를 분할할 때, 각 노드에서 특성의 무작위 선택을 사용합니다. 즉, 모든 특성을 고려하는 대신 무작위로 선택된 일부 특성만 사용하여 분할을 수행합니다. 이 방식은 트리 간의 상관 관계를 줄여주어 앙상블 성능을 향상시킵니다.
- 과적합 방지:
- 랜덤 포레스트는 여러 트리를 결합하는 방식으로 개별 트리가 과적합을 하더라도 전체 모델은 더 일반화된 예측을 할 수 있게 됩니다.
- 높은 정확도와 안정성:
- 개별 트리가 각각 약한 학습기이지만, 여러 개를 결합하면 강력한 예측 모델이 됩니다. 따라서 분류, 회귀 등 다양한 문제에서 높은 성능을 발휘합니다.
예시
- 데이터 로드
from sklearn.ensemble import BaggingRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 유방암 데이터 로드
cancer_data = load_breast_cancer()
X, y = cancer_data.data, cancer_data.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 스케일링
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
- 랜덤 포레스트 모델 구현 및 평가
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
# 랜덤 포레스트 모델 생성
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
# 모델 학습
rf_model.fit(X_train_scaled, y_train)
# 예측
y_pred_rf = rf_model.predict(X_test_scaled)
# 평가
mse_rf = mean_squared_error(y_test, y_pred_rf)
print(f'랜덤 포레스트 모델의 MSE: {mse_rf}')
- 중요 특성 확인
import matplotlib.pyplot as plt
import seaborn as sns
# 특성 중요도 추출
feature_importances = rf_model.feature_importances_
# 특성 중요도를 데이터프레임으로 변환
feature_importances_df = pd.DataFrame({
'Feature': X.columns,
'Importance': feature_importances
})
# 중요도 순으로 정렬
feature_importances_df = feature_importances_df.sort_values(by='Importance', ascending=False)
# 특성 중요도 시각화
plt.figure(figsize=(10, 7))
sns.barplot(x='Importance', y='Feature', data=feature_importances_df)
plt.title('Feature Importances in Random Forest')
plt.show()
'AI > ML' 카테고리의 다른 글
| [ML] 앙상블 학습 - XGBoost (0) | 2024.12.29 |
|---|---|
| [ML] 앙상블 학습 - 그래디언트 부스팅 머신 (GBM) (0) | 2024.12.29 |
| [ML] 앙상블 학습 - 배깅, 부스팅, 스태킹 (1) | 2024.12.29 |
| [ML] 비지도학습 - 차원축소 (LDA) (3) | 2024.12.29 |
| [ML] 비지도학습 - 차원축소 (t-SNE) (0) | 2024.12.29 |