로지스틱 회귀란?
- 로지스틱 회귀 (Logistic Regression) 은 머신러닝에서 이진 분류 문제를 해결하는 데 사용되는 통계적 모델
- 종속 변수가 이진형일때(즉, 결과가 두가지 중 하나일 때) 사용되는 통계 기법
- 선형 회귀와 달리 결과값이 0 과 1사이에 위치하게 하기 위해 시그모이드 함수(Sigmoid Function)을 사용
왜 회귀라는 이름이 붙어있는데 분류모델인가요??
- 선형 회귀와 비슷하지만 출력 값이 확률로 변환되어 0 과 1 사이의 값을 가진다
- 따라서 사건 발생 여부 를 예측하는데 활용 된다.
시그모이드 함수 (Sigmoid Function)
선형 결합의 결과인 z 값은 시그모이드 함수에 의해 변환된다.
시그모이드 함수는 입력 값 z 를 0과 1 사이의 확률로 매핑한다.
수식은 다음과 같다
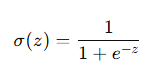
여기서 e 는 자연 상수이고
z 가 크면 1에 가까운 값을, 작으면 0 에 가까운 값을 반환한다
예측 값
- 시그모이드 함수의 결과 값은 사건이 발생활 확률을 나타낸다.
- 예를 들어, 사건이 발생활 확률 P(y = 1|x) 는
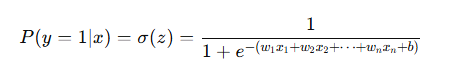
손실 함수
로지스틱 회귀는 예측된 확률과 실제 클래스 (0 또는 1) 간의 차이를 최소화 하는 방식으로 모델을 학습
이를 위해 로지스틱 손실 함수(cross-entropy loss) 를 사용
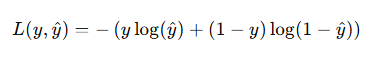
학습 과정
로지스틱 회귀는 경사 하강법 과 같은 최적화 알고리즘을 사용하여 가중치 w 와 편향 b 를 조정
이 과정은 손실 함수를 최소화 하는 방향으로 이루어진다.
로지스틱 회귀의 특징
- 이진 분류 : 주로 두개의 클래스로 데이터를 분류하는 데 사용된다
예를 들어 이메일이 스팸인지 아닌지, 환자가 질병에 걸렸는지 아닌지 를 예측하는 문제이다 - 확률적 해석 : 로지스틱 회귀는 예측 결과를 확률로 해석할 수 있기 때문에
"사건 발생 확률" 을 예측하는데 유용 - 단순함 : 모델이 비교적 간단하고 이해하기 쉬우며, 빠른 학습 속도를 자랑한다.
예시
- 데이터 전처리
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 데이터 로드
data = load_breast_cancer()
X = data.data
y = data.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 데이터 스케일링
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
- 모델 학습
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 모델 생성 및 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 평가
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
print(f"Classification Report:\n{classification_report(y_test, y_pred)}")
print(f"Confusion Matrix:\n{confusion_matrix(y_test, y_pred)}")
'AI > ML' 카테고리의 다른 글
| [ML] 지도학습 - 분류모델 (나이브 베이즈) (1) | 2024.12.29 |
|---|---|
| [ML] 지도학습 - 분류모델 (KNN) (0) | 2024.12.29 |
| [ML] 지도학습 - 분류모델 (SVM) (1) | 2024.12.29 |
| [ML] 지도학습 - 회귀 모델 (선형, 다항, 리지, 라쏘) (1) | 2024.12.28 |
| [ML] 머신러닝 이란? ( Machine Learning ) (5) | 2024.12.28 |